
Why Slack Redesigned Their Job Queue

You can read about the 'how' in this brilliantly written article by Slack engineers.
Let's focus on the 'why'!
The Context
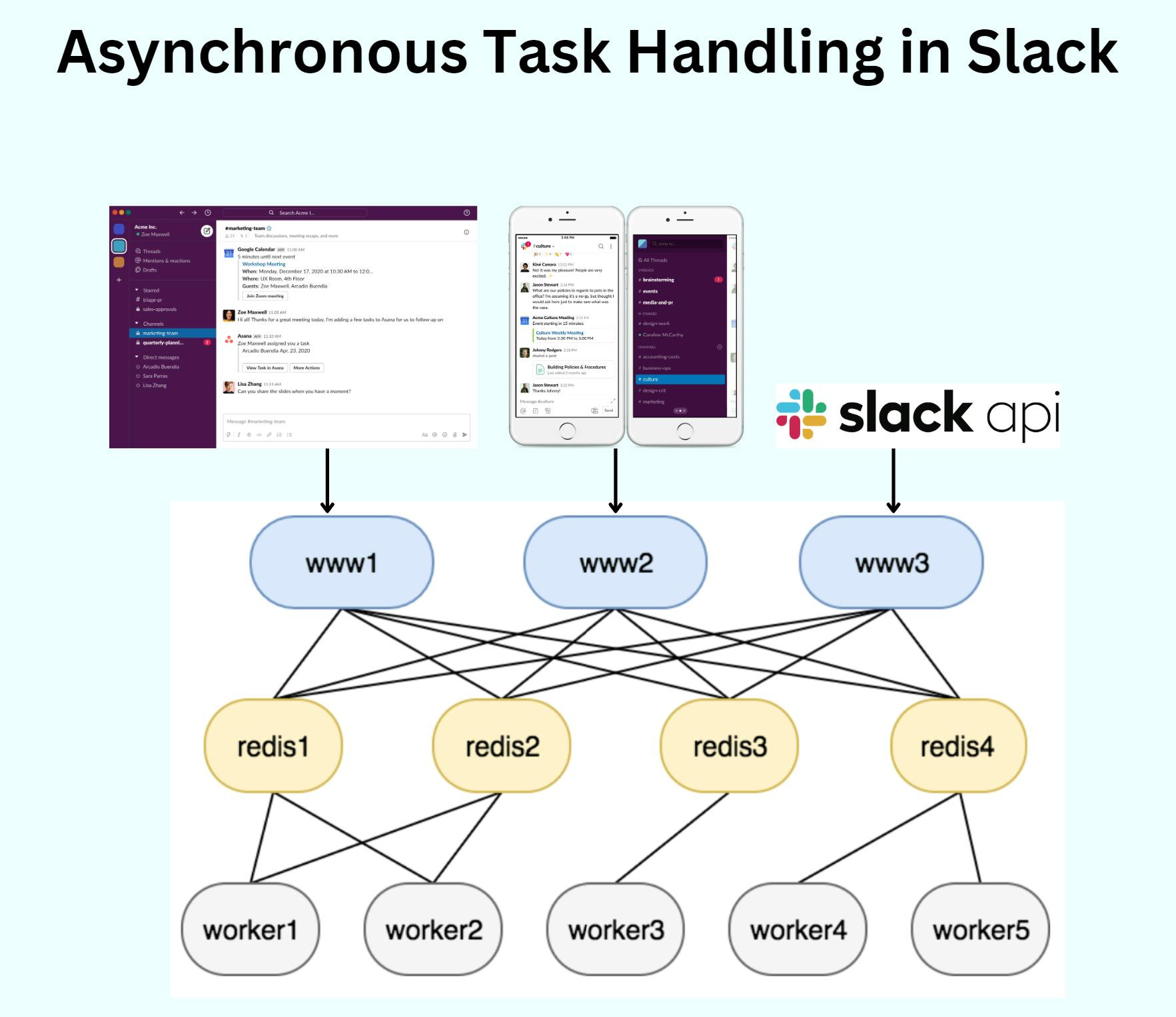
Slack handles critical web requests like message posts, push notifications, calendar reminders, billing, etc asynchronously using its Job Queue system.
6 years ago, the numbers looked something like this...
On busy days, Slack's job queue system processed over 1.4 billion jobs
The peak rate reached 33,000 jobs per second
The DAU (Daily Active Users) have grown 4X since then - it's safe to assume the number of jobs would have increased significantly as well.
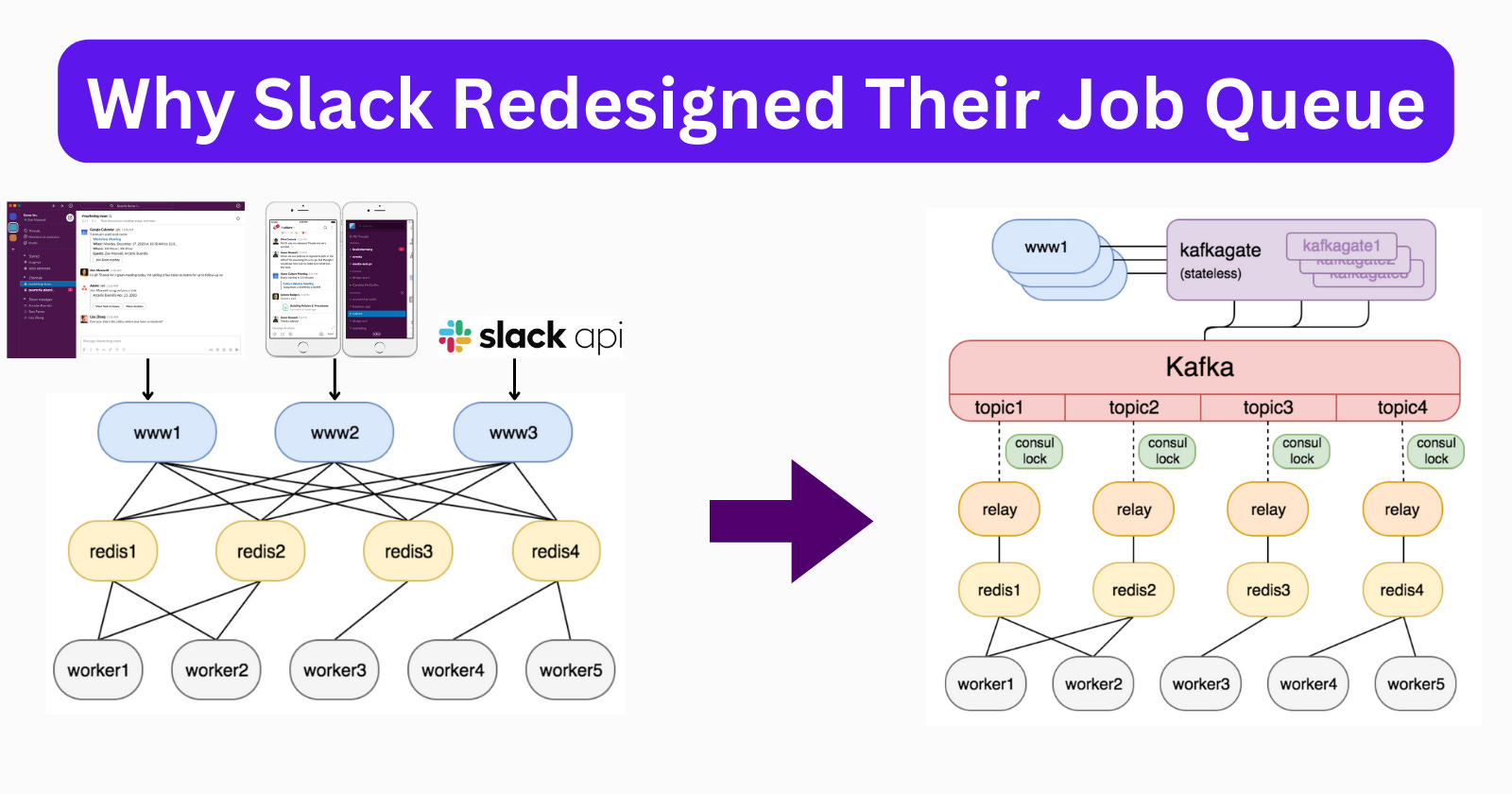
Production Outage Due to Job Queue
The Redis-based Job Queue, which was designed in the early days of Slack, served the company well until it was pushed to the limits.
6+ years ago, Slack experienced a significant production outage due to the job queue.
A resource contention in its database layer led to jobs being processed slowly.
This led to Redis running out of memory as jobs were not getting dequeued, which meant no new jobs were enqueued as well and all the downstream operations were failing.
Even though the database contention was resolved, the job queue remained locked as dequeuing also required free memory.
The Slack team managed to resolve this after 'extensive manual intervention'.
This incident led to a re-evaluation of the job queue as a whole. You can read the source article on how Slack resolved this using Kafka.
But let's understand the shortcomings of the initial design and the lessons we can take away.
Architectural Problems
After the post-mortem, the Slack team identified the below constraints. Let's double-click on a few.
Constraint 1
Redis had little operational headroom, particularly with respect to memory. If we enqueued faster than we dequeued for a sustained period, we would run out of memory and be unable to dequeue jobs (because dequeuing also requires having enough memory to move the job into a processing list).
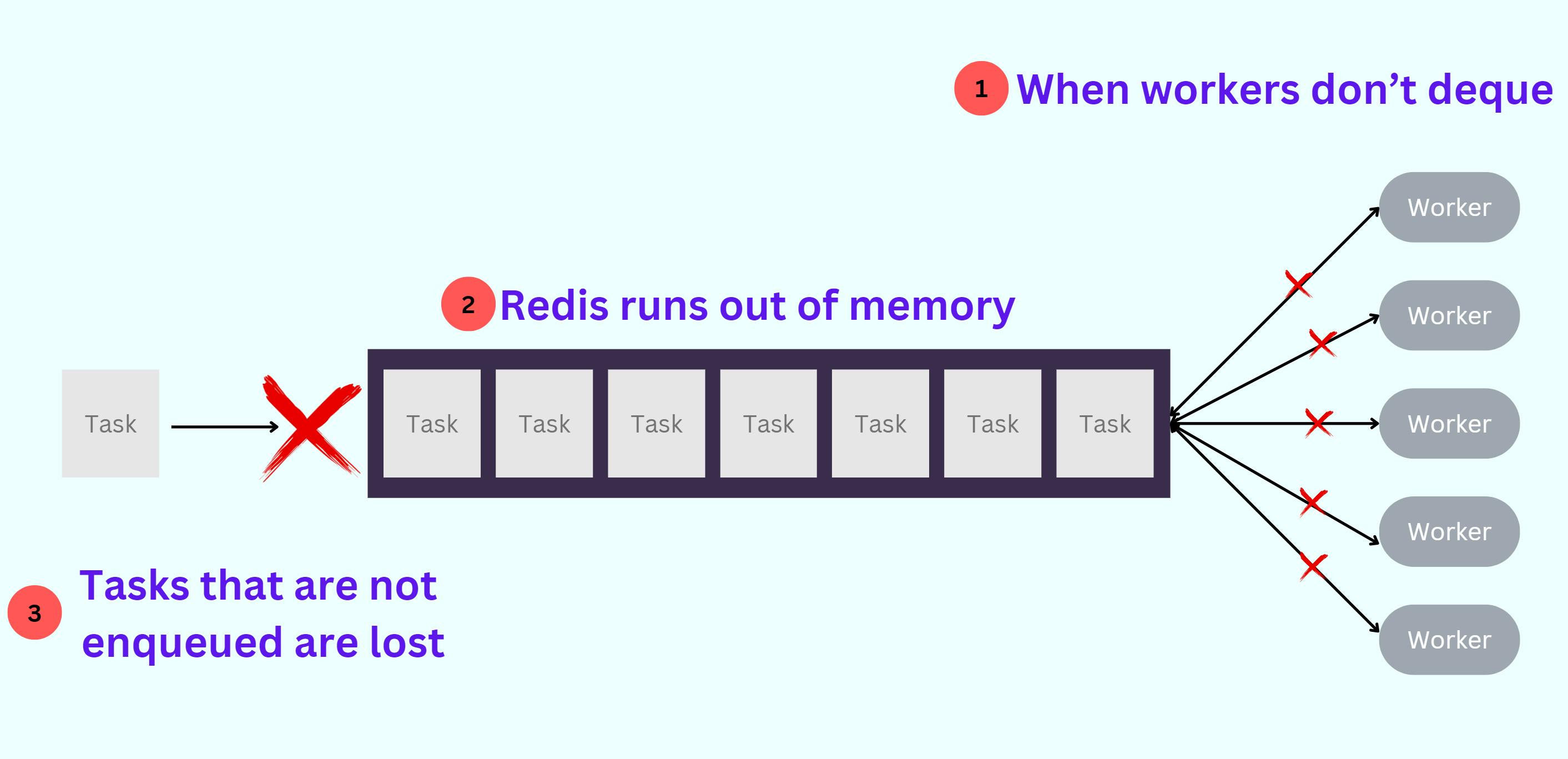
It's important to understand how Redis' behavior changes when enqueuing exceeds the rate of dequeuing.
If we continuously add more items to the queue faster than we can process them, the available memory will eventually become insufficient. This leads to two consequences:
Memory exhaustion: As mentioned, when there isn't sufficient memory left to hold both newly added elements and those waiting to be processed, Redis cannot perform dequeuing because it needs additional memory to move the job from the queue into a processing list.
Possible Performance degradation: If an eviction strategy is employed, Redis removes older/random keys. However, this results in performance issues since the data being removed might still be required by ongoing processes.
What is the right eviction policy in the scenario above?
The exact behavior Redis follows when the maxmemory limit is reached is configured using the maxmemory-policy configuration directive.
The following policies are available:
noeviction: New values aren’t saved when memory limit is reached. When a database uses replication, this applies to the primary database
allkeys-lru: Keeps most recently used keys; removes least recently used (LRU) keys
allkeys-lfu: Keeps frequently used keys; removes least frequently used (LFU) keys
volatile-lru: Removes least recently used keys with the
expirefield set totrue.volatile-lfu: Removes least frequently used keys with the
expirefield set totrue.allkeys-random: Randomly removes keys to make space for the new data added.
volatile-random: Randomly removes keys with
expirefield set totrue.volatile-ttl: Removes keys with
expirefield set totrueand the shortest remaining time-to-live (TTL) value.
The eviction policy is dependent on the business context and the business impact of the job/message, maybe certain less impactful features can have a TTL key set.
Constraint 2
Job workers couldn’t scale independently of Redis — adding a worker resulted in extra polling and load on Redis. This property caused a complex feedback situation where attempting to increase our execution capacity could overwhelm an already overloaded Redis instance, slowing or halting progress.
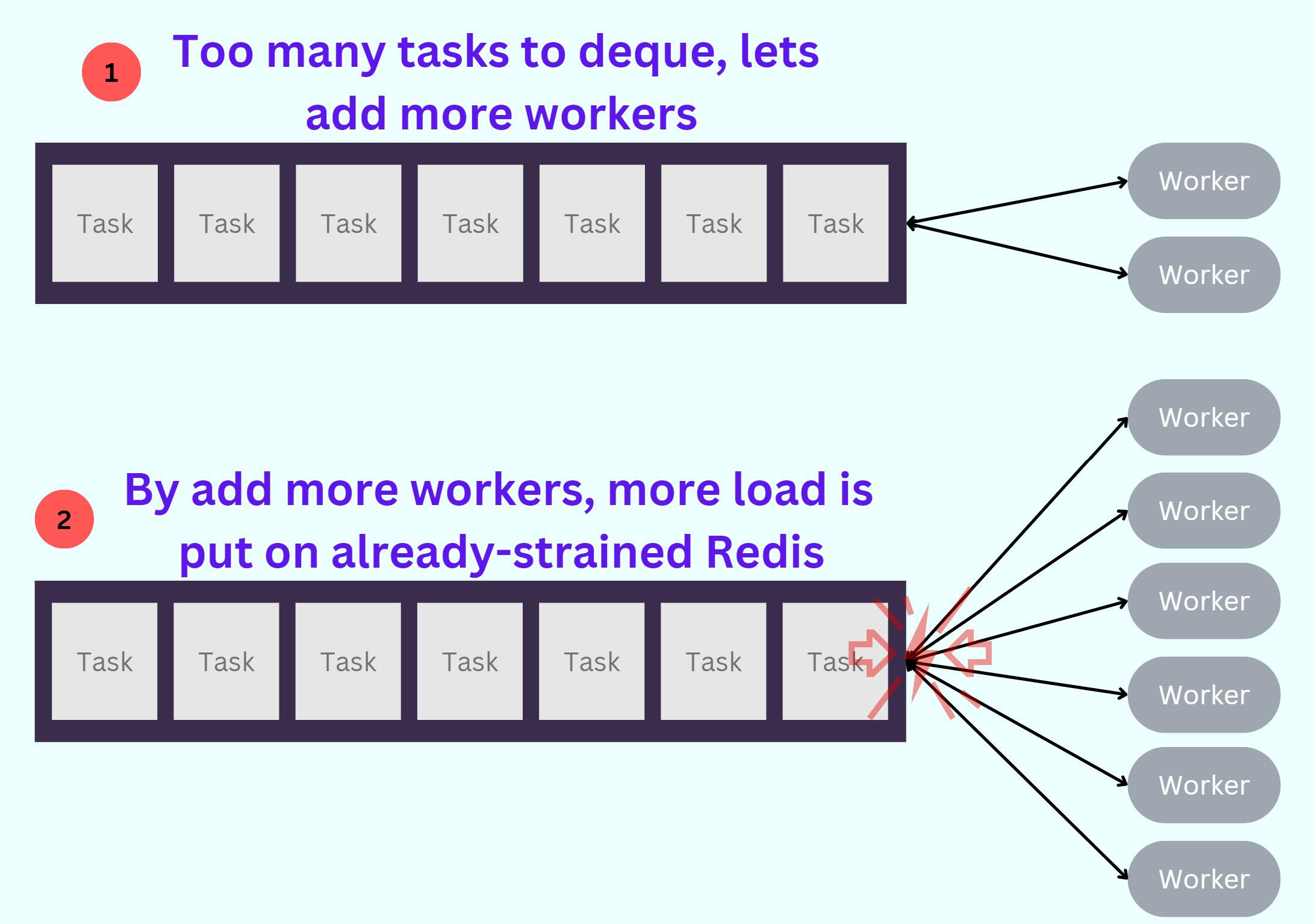
This is because Redis is a single-threaded system.
As each worker must poll Redis for new jobs to execute - the number of workers increases, the polling frequency also increases, leading to a higher load on Redis.
This can cause Redis to become overloaded, leading to performance degradation and even system failure.
Also, adding more workers to the system can create a complex feedback situation where attempting to increase execution capacity can overwhelm an already overloaded Redis instance.
To address this issue, it is essential to carefully monitor the load on Redis and adjust the number of workers accordingly.
Constraint 3
Previous decisions on which Redis data structures to use meant that dequeuing a job requires work proportional to the length of the queue. As queues become longer, they became more difficult to empty — another unfortunate feedback loop.
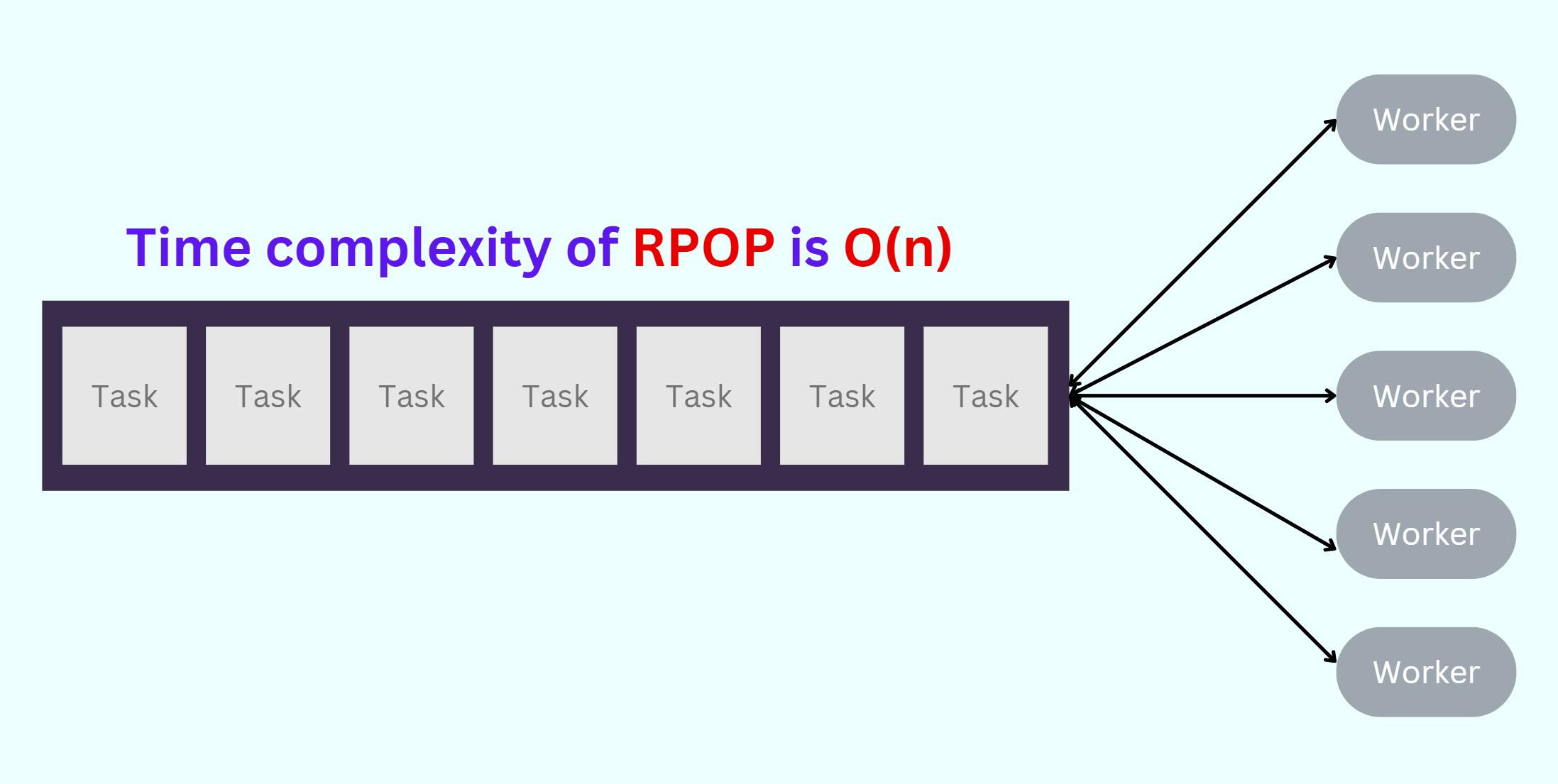
Deleting elements from a Redis list, such as a job queue, involves iteratively removing elements from the tail of the list using the RPOP command.
Since the time complexity of RPOP is O(n), where n represents the size of the list, the longer the queue gets, the more expensive it becomes to dequeue a single job. Meaning dequeuing requires free memory as well.
This exacerbated the problem, as the longer the queue got, the harder it became to keep pace with the growing demand for dequeuing jobs.
One strategy to counter this is to implement 'blocking queues' to avoid continuous polling when the queue is empty.
With blocking queues, consumers are put to sleep until a task becomes available, reducing unnecessary load on Redis
Thank you so much for investing your time in reading this article.
In the coming days, I will share tutorials on building AI agents and automation solutions.
Do not forget to subscribe if you haven't already.