


Notes From The 2024 DataHack Summit


Note: This post has a lot of pictures from the 3-day event hence the longer read time. There is a possibility that the email would appear truncated. If it does, please read this on the substack app. I appreciate your patience.
This is NOT a review of the summit but me simply sharing my notes from my favourite sessions.
Context:
I had a company-sponsored opportunity (very grateful) to attend Analytics Vidhya’s 3-day DataHack Summit. The theme for this year was…


This will quickly recap my learnings and takeaways from the 3-day event.
Note: I only attended the sessions I thought were relevant to my work. Below are notes from the top sessions I attended.
Day 1
Session: Agentic AI: The Rise of Autonomous AI Agents & LangGraph
The first session I attended was on the theme I am deeply interested in today - AI Agents
Takeaways:
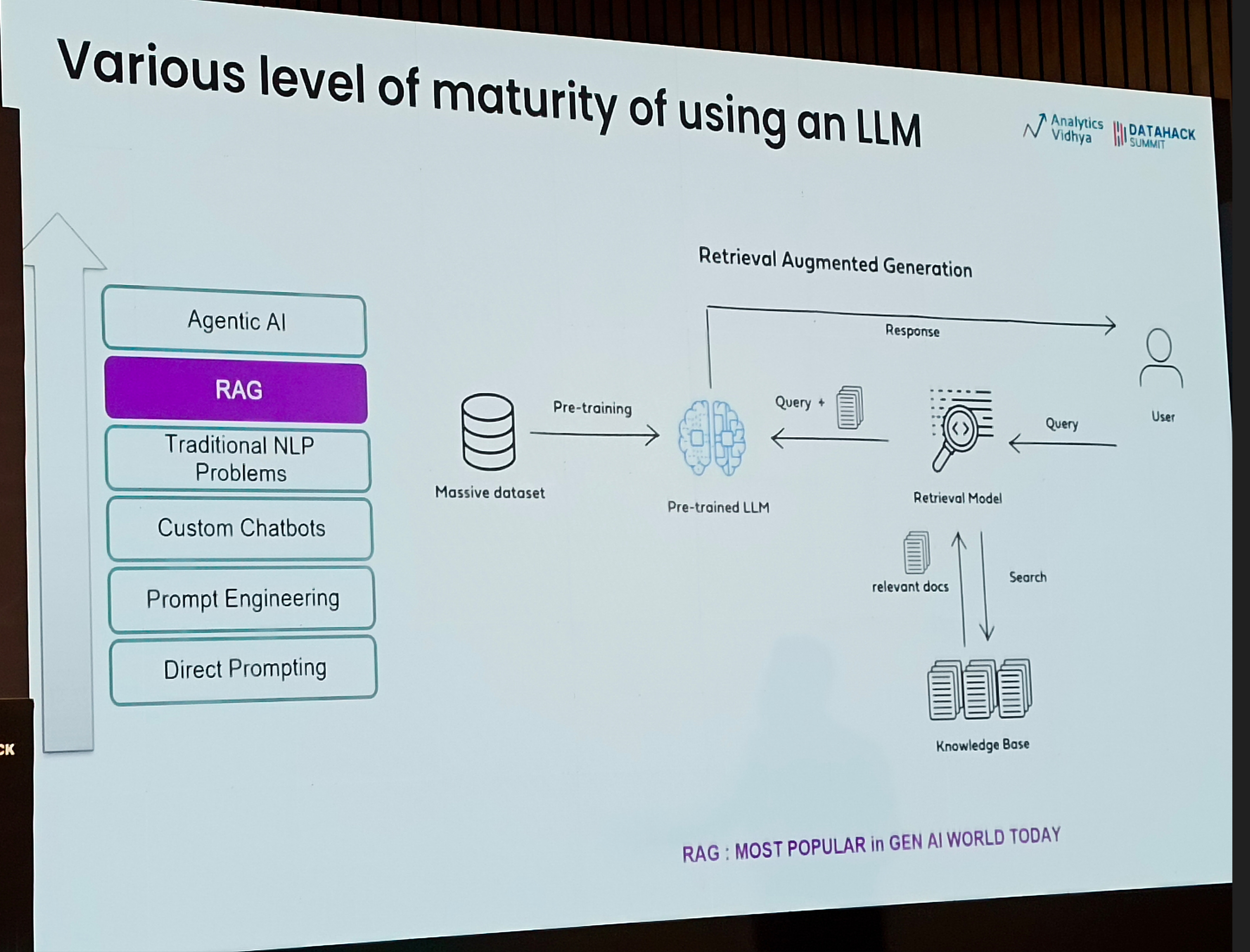
Progressive Levels of Maturity - as a team/organization, the level of maturity is a good yardstick to check where you stand. My team/organization currently is experimenting with Agentic AI - it has taken us almost a year to get here.
Plan & Execute Design Pattern

It consists of two basic components:
A planner, which prompts an LLM to generate a multi-step plan to complete a large task.
Executor(s), which accept the user query and a step in the plan and invoke 1 or more tools to complete that task.
Critique & Revise Design Pattern


Based on the paper Reflexion the idea uses a LLM to examine whether the output of another generative model used by the Agent is “on the right track” during generation.
Consider baking a cake. When you mix all the ingredients and put them in the oven, you eventually need to check on the cake.
You might open the oven door, peek inside, and see how it's rising and browning, and make adjustments accordingly.
Finally, when you take it out of the oven, you evaluate the result: Is it golden and fluffy, just as you intended?
If so, you've successfully created what you set out to make. If not, you note what changes to make next time.
Agentic RAG Architectures

Session: Improving Real-World RAG Systems: Key Challenges & Practical Solutions
I missed the first 20 minutes of this session due to an overlap with the previous one but learned a few gems from one of my favorite GenAI educators Dipanjan Sarkar.
He has open-sourced his entire slide deck here.
The most suitable RAG paradigm for your application hinges on several crucial factors:
Complexity of the task
Domain-specific requirements
Computational resources
Understanding the strengths and limitations of advanced RAG empowers you to make informed choices when building applications that leverage RAG.
By carefully considering these factors, you can harness the power of RAG to create effective and informative applications.
Takeaways
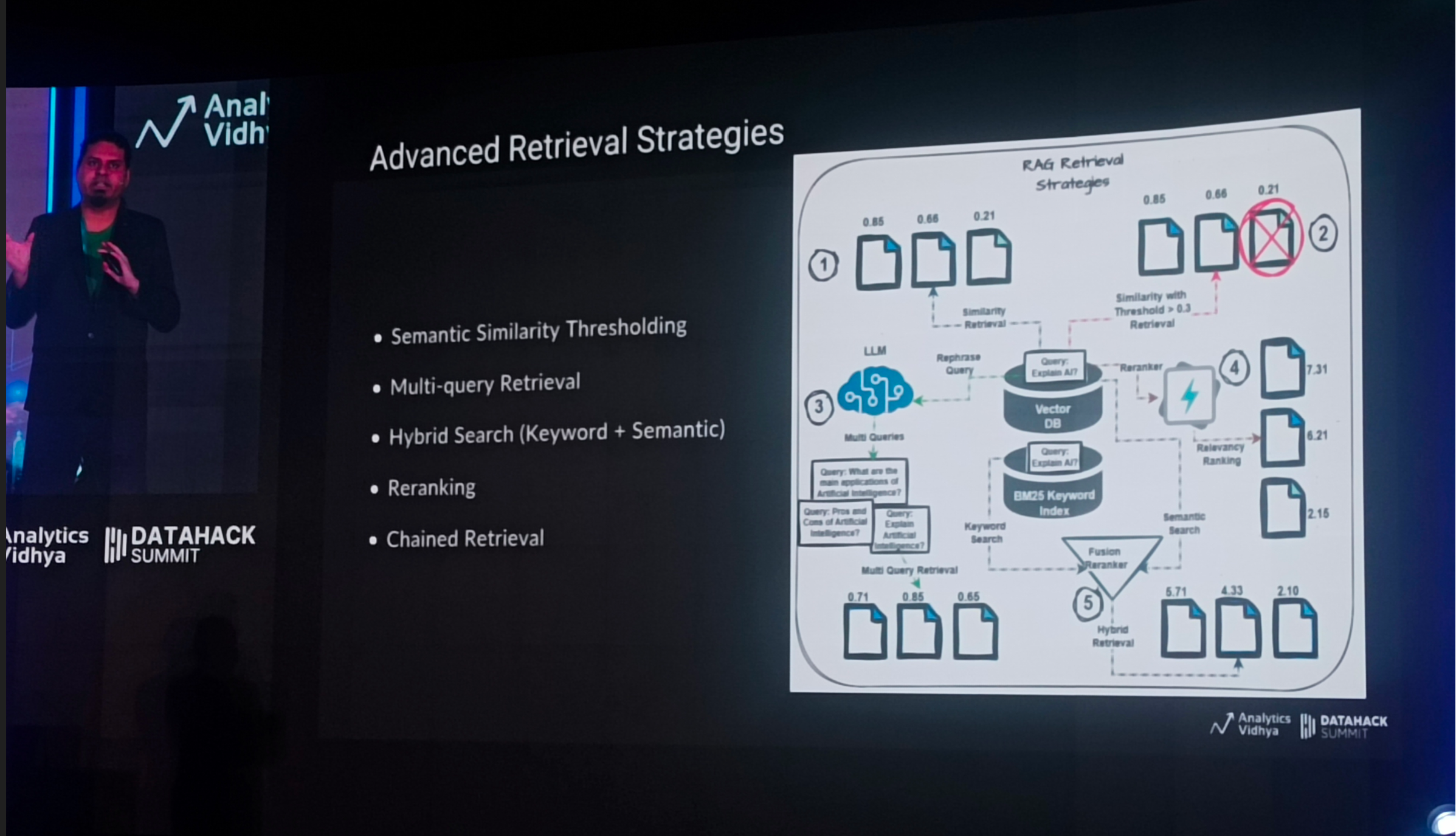
Advanced Retrieval Strategies
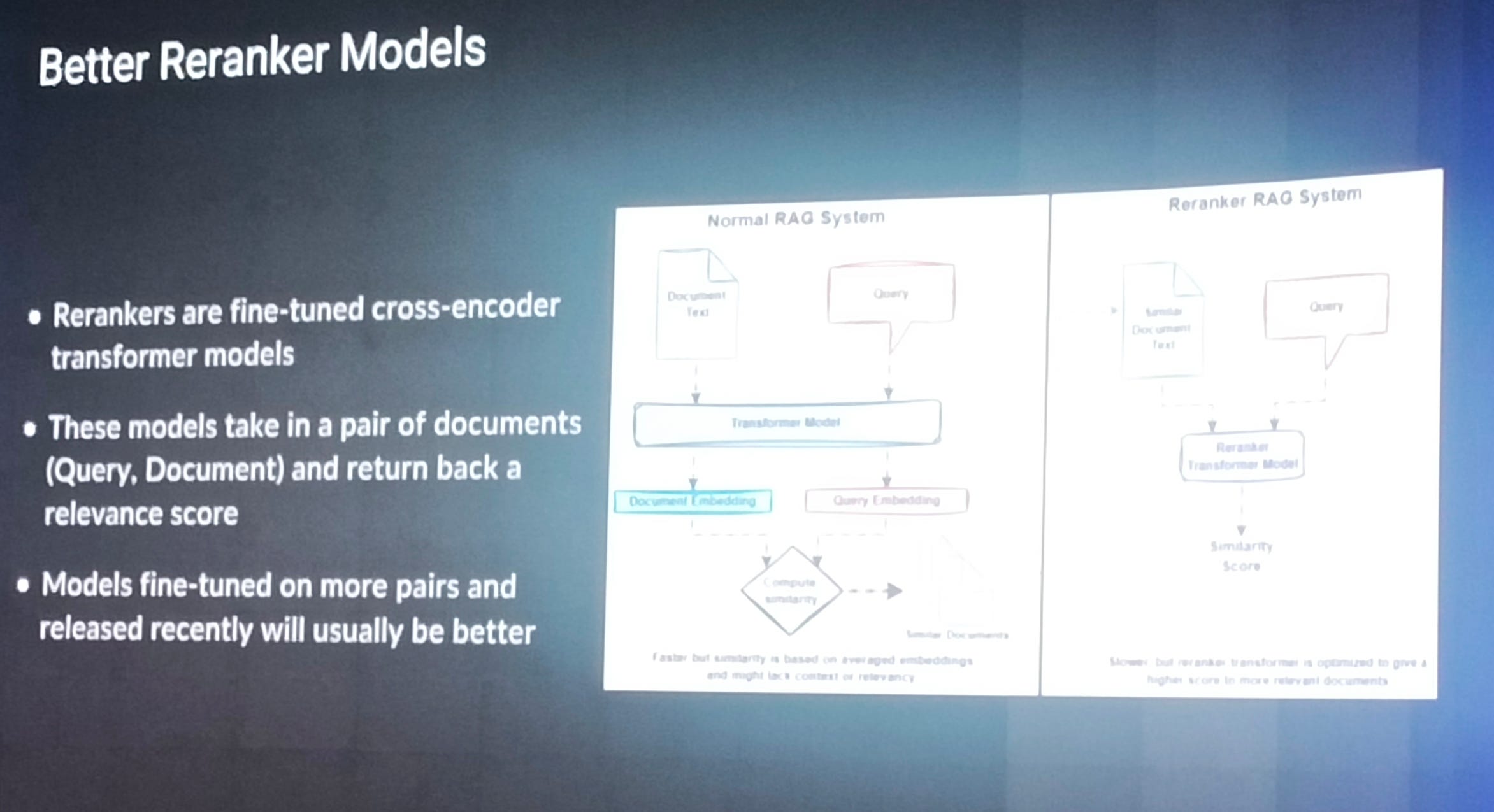
Better Reranker Models
Context Compression Strategies

Solutions for Missed Top Ranked, Not In Context, Not Extracted & Incorrect Specificity

Solutions for Wrong Format - Native LLM Support

HyDE - Hypothetical Document Embedding

Agentic Corrective RAG

Day 2
Session: GenAI Transforming Document Intelligence
Document intelligence is the use of AI and machine learning techniques to automate the extraction, analysis, and management of data from various types of documents.
This technology is increasingly being integrated into business processes to enhance efficiency, accuracy, and decision-making.
Document intelligence systems leverage Optical Character Recognition (OCR) and machine learning to extract text, key-value pairs, and structured data from documents.
This includes the ability to recognize tables, checkboxes, and other layout features, allowing organizations to convert unstructured data into usable formats quickly and accurately
My biggest takeaway from this session was learning about the open large-scale datasets for document understanding - something I wanted for my experiments.
And learning about Table-GPT and DocLLM.




Day 3
Session: Uncovering Trends from Unstructured Text Data for Enterprise with LLMs
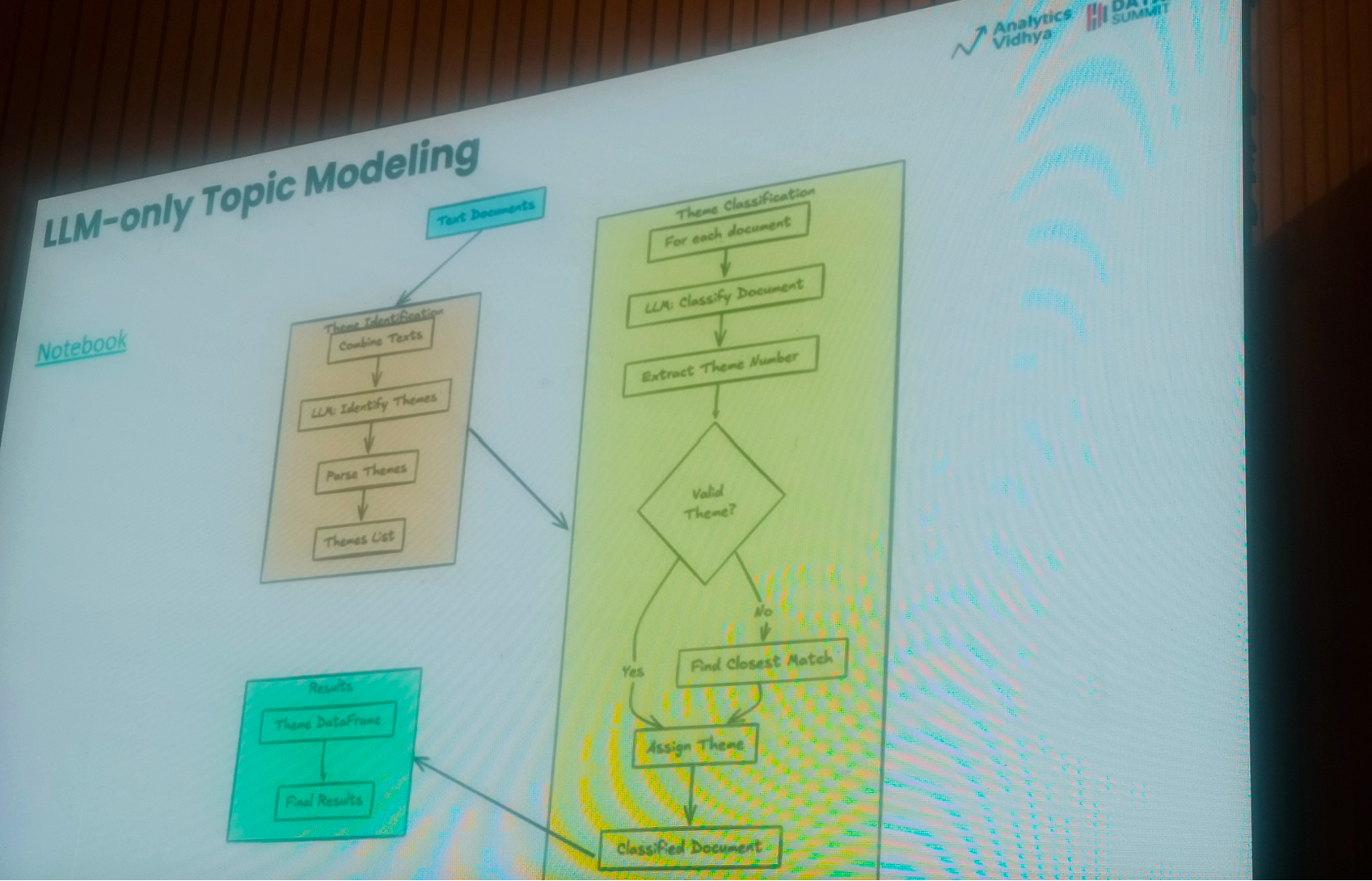
Topic modeling is a widely utilized technique for uncovering and presenting thematic structures within text data. This method is essential in fields like information retrieval, text mining, modern search systems, and data visualization, enabling researchers to efficiently explore large textual datasets. Over time, various approaches have been developed to enhance the analysis of textual data and uncover hidden themes, including Latent Dirichlet Allocation (LDA), LDA with WordNet, Neural Networks, Linguistic Extensions, BERTTopic, and KeyBERT.
However, before the emergence of large language models (LLMs), topic modeling encountered several challenges:
Lack of labeled data
Limited understanding of context
Difficulty in interpreting topics
Inflexibility
Limited scalability
Absence of pretrained models
In this session, I learned how to leverage LLMs for topic modelling.


Conclusion
Attending the 3-day GenAI summit was an incredibly enriching experience.
Events like this are invaluable for staying at the forefront of emerging technologies, expanding your professional network, and gaining fresh insights from industry leaders.
They provide a unique opportunity to learn about the latest advancements, exchange ideas with like-minded professionals, and explore new ways to apply AI in your work.
Whether you’re looking to deepen your knowledge, collaborate on innovative projects, or simply stay ahead in a rapidly evolving field, attending such summits can be a significant step toward achieving those goals.
Some of My Popular Posts
The New Non-Negotiable: Embracing Adaptability

I was once talking to a friend whose brother was pursuing a master's degree in medicine.
Why Slack Redesigned Their Job Queue

You can read about the 'how' in this brilliantly written article by Slack engineers.